

A Proposal for a Two-way Journey on Validating Locations in Unstructured and Structured Data
An exciting, diverse international collaboration
In July 2018, a group of young researchers met in the castle-turned-campus of the International Semantic Web Research Summer School (ISWS) in Bertinoro, Italy. The group included computer scientists, computational linguists, philosophers, and social scientists from all over the world, including Italy, the Netherlands, Germany, Turkey, Brazil, Egypt, Algeria and Jordan. It was a multi-lingual, diverse and interdisciplinary collaboration. During five days, the team led a collective brainstorming effort to come up with interesting research questions and to organized the work process so that each team member could best perform a task based on his/her skills and ideas. It was a great opportunity to get to know each other and grow both as researchers and as people!
During this time together, the team came up with the main idea and the preliminary work, including the approach as well as the choice of the corpus and datasets to deal with. We chose to look at a corpus of historical writings: the diaries of English-speaking travelers in Italy between 1867 and 1932, named “Two days we have passed with the ancients… Visions of Italy between XIX and XX century.”
What’s the problem?
The starting point was finding a way to validate textual (unstructured) data and Linked (structured) Data from the point of view of Natural Language Processing (NLP). So we applied NLP-based methods to extract the names of locations from the diaries, which were the names used in the traveller’s time. Then, we linked those names – our ‘entities’ – to the structured Linked Data from DBpedia and GeoNames in order to validate the extracted data.
At the end of the week, we described the results of this preliminary study on the intersection between NLP and Linked Data, based on the definition of validity, in a dedicated research report, which is part of a general report on Linked Open Data Validity investigated from different perspectives.
Building on our start
After, a part of the group decided to continue working on the subject in order to write a paper together. We kept on collaborating at a distance for several months, meeting by skype and sharing our work under the direction of our supervisor Marieke. We did further experiments and it led to a position paper describing both the approach, with its strengths as well as its weaknesses, and more examples of validated extractions.
Our collaborative work, entitled A Proposal for a Two-way Journey on Validating Locations in Unstructured and Structured Data, co-authored by Ilkcan Keles, Omar Qawasmeh, Tabea Tietz, Ludovica Marinucci, Roberto Reda, and Marieke van Erp, was accepted for the conference Language, Data and Knowledge (LDK) 2019 in Leipzig, a great end to our hard work!
What’s new about our approach?
Typically, the NLP approach with unstructured data and the linked data used in the semantic web technologies have been kept seperate. What we wanted to do was to find a way to combine them in order to validate both types of data together.
Figure 1 depicts the experimental workflow showing how NLP can be utilized to assess two different issues of both textual data validity and Linked Data validity.
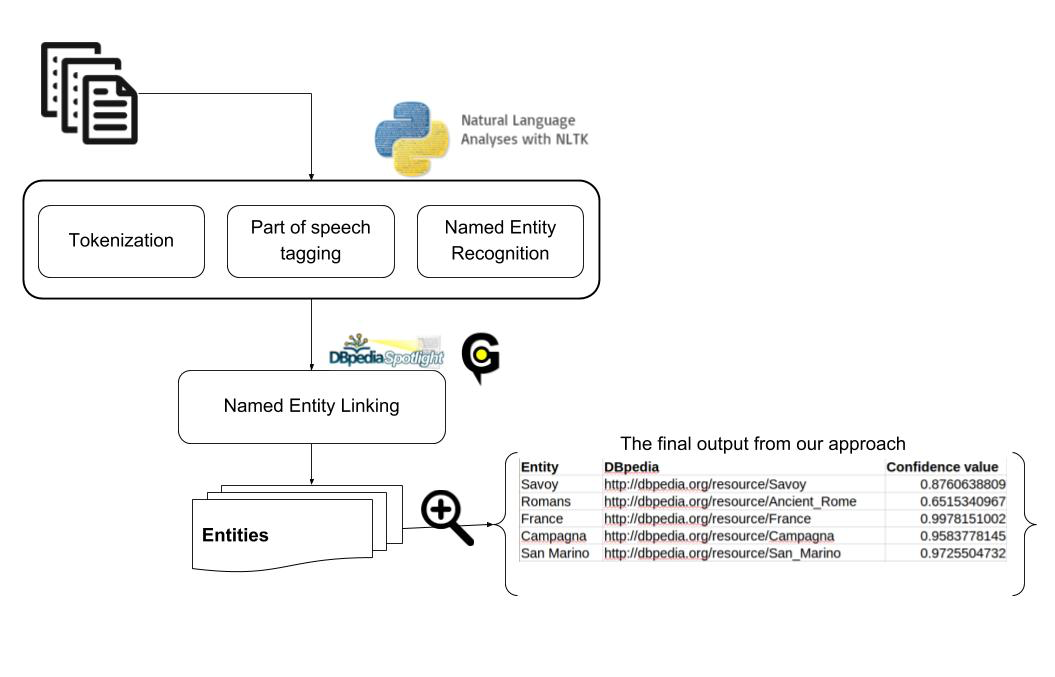
Figure 1: Natural Language Processing workflow
Figure 2 shows the number of location entities, the number of entities linked using GeoNames and the number of entities linked using DBpedia for each file. The text under each column-group corresponds to the title of the document of the historical writings.
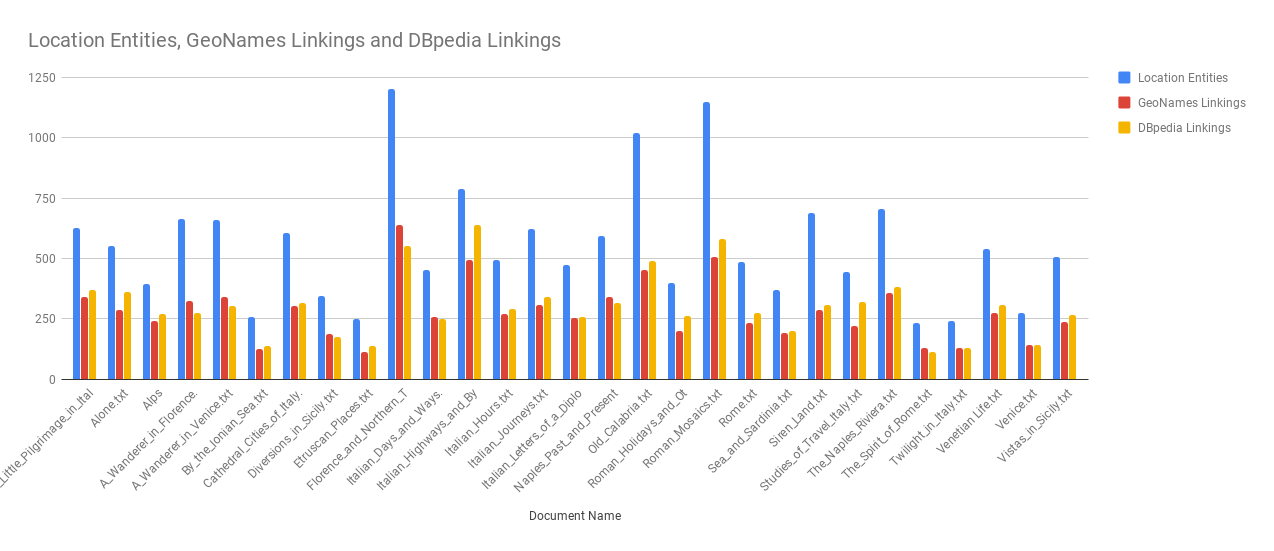
Figure 2: Number of Entities and Entity Linkings from GeoNames and DBpedia
The number of entity linkings from GeoNames and DBpedia is quite dependent on the content of the document. In half of the documents GeoNames performs slightly better than DBpedia and vice versa. Therefore, it cannot be clearly stated that one of the selected structured database works better than the other one for the textual data validity of documents regarding geographical entities.
However, we have found an example corresponding to a name change of a location in Sicily. The previous name was Monte San Giuliano and now it is called Erice. When we lookup the name of Monte San Giuliano from GeoNames, we managed to find the contemporary location entity due to the fact that GeoNames contains the information regarding old names. However, it was not possible to locate this entity in DBpedia. For this reason, if the entities are extracted from documents corresponding to historical information, it would be better to utilize GeoNames database.
What’s next?
There are still some challenges for these approaches, but this is a promising first step. In the future, we want to build on this and focus on aspects of validity for different types of information.
We plan to extend our experiments by enriching the dataset with entity links in order to assess the precision and work towards automating data validation. As our initial linking experiment showed that both DBpedia and GeoNames have insufficient coverage for historical location names, we have to use different databases to compare with and include other domains. We also want to investigate which properties and historical information about the extracted locations can be useful to further automate the validation process.
On Wednesday 22 May, Omar will present our work and future plan at LDK 2019 and we will add the link to the proceedings as soon as they are published!
Ludovica Marinucci